
【初心者向け!】SEOの内部対策を徹底解説!

ウェブサイトの評価はすべて検索エンジンが決めています。
検索エンジンがウェブサイトの評価をするうえで一番重要なことはコンテンツの質です。
なのでユーザーのことを第一に考えて品質の高い情報を提供していれば、
検索エンジンに評価されるサイトになります。
しかし、検索エンジン(ロボット)と人間では見えているものが違います。
人間から見て「このウェブサイトはすごく良い」と思ったことが
ロボットから見た場合、正しく評価されないことがあります。
なのでウェブサイトを検索エンジンに正確に伝えるために、サイトの内部を最適化する必要があります。
この記事では、この人間とロボットのギャップを埋めるために必要な内部SEO対策について解説します。
SEOについてよくわからない方は次の記事を参考にしてください。
SEOの内部対策(HTML)
まずSEOの内部対策の基本としてHTMLファイルを見直しましょう。
Googleのクローラーは基本的にはHTMLファイルから情報を収集するのであって、
我々が目にするブラウザから情報を収集しているわけではありません。
なのでユーザーが見て「このウェブサイトはすごくデザインがいいな」と思うようなサイトがあったとしても
ウェブサイトのデザインは一切SEOには関係ありません!
なのでHTMLファイルをまずは検索エンジンに評価されるように改善していきましょう。
titleタグの最適化
まずはtitleタグの最適化です。titleタグはウェブサイトのページのタイトルを設定するために利用されるhtmlタグです。
titleタグは次のように検索したときに青文字で表示されます。

このtitleタグを最適化するうえで意識するべきところは
・タイトルの文字数を長くしすぎない
・重要なキーワードはなるべくタイトルの前方に記述する
・ウェブサイト内に似たようなタイトルをつけない
タイトルを長くしすぎると検索結果で後半の部分で「…」と表示されてしまいます。
なので重要な情報やキーワードはタイトルの前方に記述するとよいでしょう。
またウェブサイト内に似たようなタイトルがたくさんあると
・検索エンジンに重複ページとみなされてしまう可能性がある
・ウェブサイトの評価が分散されてしまう
といったデメリットがあります。特に重複コンテンツと判断されてしまうと最悪の場合Googleからペナルティを受ける場合があります。
ですので1ページごとに個別のタイトルをつけるように心がけましょう。
URLの最適化
URL名のつけ方にも最適化する要素がたくさんあります。
URLを最適化するうえで意識するべきところは
・コンテンツに関連した名前を英語でつける
・簡潔なURLにする
・単語を区切るときにハイフン「-」を使う
・トップページから3クリック以内で移動できるようにする
まず全体的に言えることはわかりやすいURLはページの情報を伝えやすいということです。
英語でつけることの理由は文字化けやシステム上の不都合が起こらないようにするためです。
実際のところ、日本語のURLはSEOで見ると悪影響はないみたいですが、SEO以外の部分でのデメリットがあるのでなるべく英語のほうが良いです。
Googleは公式でハイフン「-」を利用することを推奨しています。ハイフンを使うことで単語ごとに認識されるためページの内容を正しく伝えやすいです。
トップページから3クリック以内で移動できるようにするについては、
クローラーから「重要ではないページ」として扱われてしまう可能性を回避することと、
ユーザビリティーの向上のためです。
パンくずリストの設定
パンくずリストとは現在表示しているページの位置を示すために、ページ上部に設置されているリストのことです。
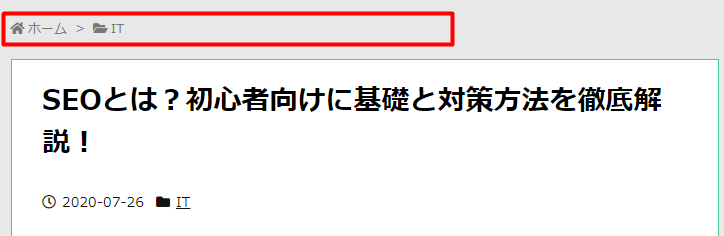
パンくずリストはトップページ以外からページに訪問してきたユーザーが、
現在のページがどのカテゴリーに属しているのかを理解しやすくなります。
また検索エンジンから見るとパンくずリストは内部リンクにあたるため、
検索エンジンがウェブサイト内をクロールするときにページ内部を効率よくクロールできます。
効率の良いクロールをすることで、各ページコンテンツに対して評価を得ることができます。
そのためパンくずリストはユーザーにとっても検索エンジンにとってもよい評価を得ることができるので、ぜひ設置しておきましょう。
URLの正規化
検索エンジンは重複するページに対してページの評価を分散させたり、ペナルティを与えたりします。
なので重複ページを作らないようにすることはSEOの基本です。
しかし、知らず知らずのうちに重複ページを作ってしまっている可能性があります。
検索エンジンはwww.の有無やhttpとhttpsなどをそれぞれの個別のページとして認識します。
検索エンジンから見ると
・http://example.com/
・https://example.com/
・http://www.example.com/
これらは別々のページと認識します。
先ほど解説したように、重複ページがあることは望ましくありません。
そのため、これらのURLをすべて同一のページであるとするための作業をURLの正規化と言います。
では、どのようにして正規化すればよいのでしょうか?
URLの正規化の方法としては次の2つがあります。
・301リダイレクト
・canonical設定
Googleは基本的に301リダイレクトを推奨しており、301リダイレクトができない場合はcanonical設定を行うことを認めています。
しかし301リダイレクトの設定は基本的にサーバーでの設定を行います。
レンタルサーバーでは簡単に設定できるものがありますが、301リダイレクトができないサーバーもあります。
個人や企業でサーバーを所有している場合、
PHPなどのサーバーアプリケーションで設定するなど初心者が手を加えにくい部分があります。
ですのでここではcanonical設定のやり方について解説します。
- http://example.com/
- https://example.com/
- http://www.example.com/
この3つのURLのうちhttps://example.com/を正規ページ(評価を集中させたいページ)にしたい場合、重複しているページである
http://example.com/
http://www.example.com/
の2つのページのheadタグに次の記述を行ってください。
<head>
<link rel="canonical" href="https://example.com/">
</head>hrefの値に正規ページのURLを間違いがないように記述してください。
この部分が間違っていると存在しないページを正規ページとしてしまい、検索エンジンからの評価が下がる可能性があります。
SEOの内部対策(HTML以外)
HTMLファイルの対策以外にも内部SEO対策で行うことはたくさんあります。
ただ、これらのことは専門的な部分があり、初心者には難しい部分があります。
robot.txtの設置
robots.txtはクローラーのアクセスを制限する設定を記述するファイルです。
robots.txtの大きな役割として、クローラーが巡回してほしくないページを指定することができます。
クローラーが巡回してほしくないページとして次のようなものがあります。
・管理用のページ
・検索結果に表示させたくないページ
・パスワードが必要なページ
クローラーが巡回すると検索エンジンにウェブページの情報が登録され、検索結果に表示されるようになりますが、
これらのページを検索結果に表示させてしまうと、管理側にもユーザー側にもデメリットしかありません。
なのでrobots.txtにクローラーに対する命令を記述して、アクセスを制御することが必要です。
robots.txtの設置場所についてはサイトのルートディレクトリ(https://example.com/robots.txt)です。
ではrobots.txtに
どのクローラーに対して、どのページの巡回を許可し、どのページを禁止するか
について個別で記述方法を見ていきましょう。
User-agent設定
実はクローラーと言っても色々な種類があります。Googleではキーワードで検索するとき
・画像検索
・動画検索
・ニュース検索
のように様々な検索をすることができます。実はこれらすべてに個別のクローラーがあります。
もちろんGoogle以外の検索エンジンにも個別のクローラーがあります。
そのためどのクローラーに対して命令を出すのかを制御する必要があります。
その命令に利用されるのがUser-agent設定です。
基本的には管理用のページやパスワードが必要なページは、すべてのクローラーが巡回してほしくないものであると思います。
このすべてのクローラーに対して命令を行いたい場合、
robots.txtに次の記述を行ってください。
User agent: *
「*」を記述するとすべてのクローラーに対しての命令となります。
限定的ではありますが、特定のクローラーに対して命令をしたい場合もあります。
写真等をGoogle画像検索の結果に表示させたくない場合は、画像用のクローラーに対して命令をしなければなりません。
このような場合は「*」のかわりに固有の識別子を記述する必要があります。
| クローラー | 識別子 |
| Googlebot | Googlebot |
| 画像用Googlebot | Googlebot-Image |
| 動画用Googlebot | Googlebot-Video |
| ニュース用Googlebot | Googlebot-News |
Allow・Disallow設定
どのクローラーに対して命令を出すのかを決定したら次は巡回を許可するのか禁止するのかを指定します。
例えば試験用のページがいくつかhttps://example.com/test/の中にあって、
それらのページを検索結果に表示させたくない場合は、
robots.txtのUser-agentの下の行に次のように設定を行います。
Disallow: /test/
他にもURLの末尾が.pdfであるPDFファイルを巡回させたくない場合は次のように設定を行います。
Disallow: /*.pdf$
「/*.pdf$」の「$」は末尾を意味しています。つまりこの命令は
.pdfを末尾($)にもつすべて(*)のページの巡回を禁止(Disallow)するという意味になります。
デフォルトは許可をするようになっていますので、Allowは設定しなくてもよい場合があります。
ですが、巡回を禁止している中で例外的に許可したいページがある場合にAllowは使われます。
例えば先ほどの試験用のページがhttps://example.com/test/の中にあって、
その中のsample.htmlファイル以外を検索結果に表示させたくない場合は、
Disallow: /test/
Allow: /test/sample.html
のように書くことで/test/にあるファイルは巡回を禁止するが、
/test/sample.htmlだけは巡回を許可するというようになります。
またAllowとDisallowの順番は逆でも同じ意味になります。これはAllowとDisallowの優先順位に
具体的に書いてある方の優先順位を高くするというものがあるためです。
この場合ですと、Allowのほうが範囲を具体的に書いてあるので/test/の中にあるsample.htmlファイルはAllowのほうが優先されます。
またrobots.txtの役割の1つとしてXMLサイトマップのURLを伝えるということがあります。
XMLサイトマップについては次節で解説します。
XMLサイトマップの設置
XMLサイトマップとは、ウェブサイト運営者が検索エンジンに向けてページ一覧のURLをまとめて伝えるためのファイルです。
XMLサイトマップには、各ページのURLやページの重要度、最終更新日などの情報があり、クローラーが自分のサイトを巡回するのに役立ちます。
クローラーは基本的にサイト内のリンクをたどることで各ページを巡回しています。しかし、リンクがされていない独立したページがあるとそのページを巡回しない場合があります。
こういったことを防ぐために、ページ一覧のURLをまとめて伝えるためのファイルが必要になってくるのです。
なのでサイトのページ数が多くなったり、頻繁にページを更新する場合にはXMLサイトマップは必須になってきます。
それではXMLサイトマップの設置方法について解説していきます。
まずウェブサイト作成にWordpressを利用している場合は、
Google XML Sitemapsというプラグインを利用することを強くおすすめします。
Google XML Sitemapsを使うとXMLサイトマップがページを更新する度に自動で生成し更新してくれます。
なのでプラグインをインストールしてしまえば、あとは自分でファイルを操作する必要がなくなります。
ウェブサイト作成にWordpressを利用していない場合は、
自分で1から作成するか、ツールを使って自動で作成するかになります。
基本的に自分で1から作成するのは手間がかかるのでおすすめしません。
時間の短縮のために、ツールを使うことをおすすめします。
XMLファイル(ファイルの名前は何でもいいですがここではsitemap.xmlとします)を作成したら、最後に作成したXMLファイルをhttps://example.com/sitemap.xmlに設置します。
そしてXMLファイルがどこにあるかをクローラーに知らせるためにrobots.txtに次の記述を追加します。
Sitemap: https://example.com/sitemap.xml
HTTPS化
ウェブサイトには
http://example.com
https://example.com
のようにhttpから始まるウェブサイトとhttpsから始まるウェブサイトがあります。
この2つの違いは結論を言ってしまえば
httpから始まるウェブサイトは通信が保護されていない
httpsから始まるウェブサイトは通信が保護されている
これはhttpから始まるサイトでカード番号やパスワード等の個人情報を入力してしまうと
第三者から個人情報が盗み見られる可能性があることを意味しています。
こういった通信面での信頼性の低いウェブサイトがトップページに表示されるのは好ましくありません。
なのでGoogleは、httpsから始まる信頼性の高いウェブサイトを優先すると公式で発言しています。
Google Chromeではhttpsから始まるウェブサイトには「この接続は保護されています」という文字が表示されます。
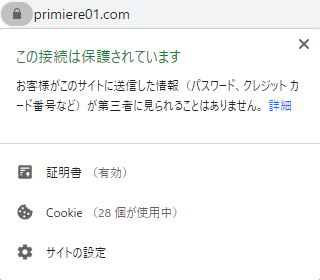
一方で、httpから始まるウェブサイトは「このサイトへの接続は保護されていません」と表示されます。たとえ、検索順位に関係がなかったとしても、こういった表示がされるサイトにはアクセスしたくはないと思います。
なのでサイトのhttps化は重要な課題であると言えます。

実際にhttps化をするにはサーバーのほうの設定をする必要があります。
レンタルサーバーの場合は、自分の借りているサーバーのアカウントにアクセスして、「SSL設定」などの設定からhttps化をすることができます。
自分でサーバー所持している場合は、自身で1から設定する必要があります。
ウェブサイトの表示速度の改善
物事を調べようとするとき、ウェブサイトの表示速度が遅いと、ユーザーはページが開く前に離脱してしまうことがあります。
どんなにコンテンツの質が良くても、ページの表示速度が遅いだけでウェブサイトを見てもらえなくなってしまいます。
Googleはユーザーファーストを第一に考えており、ウェブサイトの表示速度も検索順位の評価の1つに入っています。
また検索順位だけでなく、ユーザーの満足度にも大きな影響を与えます。
実際にAmazonでは表示速度が0.1秒改善されると、売り上げは1%増えるというデータがあります。
そのため表示速度を改善することは、検索順位や満足度の向上に大きくかかわってきます。
では、ページの表示速度の改善はどうすればよいのでしょうか?
サーバーの応答時間の改善
まずはサーバーの応答時間についてです。無料のレンタルサーバーとかを借りていると、応答時間がかかることがあります。
その場合はレンタルサーバーを変えるだけでも大きな改善が見込めます。
画像の圧縮
ウェブページの容量の多くは画像によるものです。
そのため画像を圧縮してファイル容量を小さくすることでウェブページの表示速度の改善をすることができます。
特にサイズの大きな画像を使っていると表示速度が遅くなりがちです。
適切なサイズの画像を圧縮して利用するのが良いでしょう。
不要なプラグインの削除(Wordpressを使っている場合)
WordPressを使っている場合、プラグインはなくてはならないものです。
しかし、プラグイン同士の相性関係が原因でウェブサイトの表示速度が遅くなっている場合があります。
そのため、不要なプラグインは削除するのが良いでしょう。
目安としてプラグインは10個以内をおすすめします。
まとめ
この記事ではSEOの内部対策について解説しました。
これらの手法は検索順位を上昇させるのに役立ちますが、一番重要なのはコンテンツの質です。
高品質なコンテンツを正しくクローラーに認識させるのがSEOの内部対策の目的であって、これらの内部対策をすべて行えば、コンテンツの質が低くても検索順位が上昇するものではありません。